A campeã de uso, pois é em postagens anteriores relacionei arvore a banco de dados e essa estrutura é a mais usada em SGBDs, nesse caso aumentamos a nível de exigência, antes na arvore binaria, o grau era dois mas inserir elementos era feita de maneira live leve e solta, sendo assim agora vamos restringir ainda mais,
essa ED usa o conceito que todos os elementos a esquerda do nó pai é menor que o valor nó pai ( não vou especificar em números pois a chave quem implementa é o programador) e os valores da direita são maiores que o valor do pai então e se for igual ? depende da implementação do programador se vai ou não aceitar chaves repetidas e se aceitar como ria proceder com ela, então segue o material :
Árvores Binárias de Busca
Definição: É uma árvore binária em que todos os valores na subárvore esquerda são menores que o da raiz e todos os valores da subárvore direita são maiores (ou iguais) que o da raiz.
Exemplos de árvores binária
s de busca:


Usando o caminhamento central, teríamos:
Seqüência (1° árvore): A, B, C, D, E, F e G.
Seqüência (2° árvore): 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 e 110.
Implementação de uma Árvore Binária de Busca
A função
EncontrarChave busca na árvore passada a chave informada. Se encontrar,
P apontará para o nó que a contém e a função retorna
true. Caso não encontre, a função retorna
false e
P aponta para o nó que seria o seu pai caso existisse.
A função
Inserir usa
EncontrarChave para verificar se a chave já existe. Caso exista, retorna
false. Se não existir, aproveita o apontador
P (aponta para o pai correto do nó a ser inserido) e inclui na subárvore esquerda de P se a chave sendo inserida for menor ou na direita se for maior, retornando
true.
A remoção de um nó pode ser mais simples ou complexa de acordo com o número de subárvores que possui.
a) Removendo um nó sem subárvore (folha):

Nesse caso, basta apagar o nó e atualizar o apontador para ele no pai para
nil.
b) Removendo um nó com uma subávore:

Nesse caso basta desviar o apontador que apontava para o nó a ser removido para a sua única subárvore. Por último, elimina-se o nó.
c) Removendo um nó com duas subávore:

Nesse caso é necessário encontrar o
sucessor imediato, copiar o seu conteúdo para o nó a ser removido e remover o nó que continha o sucessor imediato.
Para remover um nó nesse caso teremos que colocar um outro nó no lugar daquele que vai ser removido. Para a escolha desse nó podemos usar duas abordagens:
- Sucessor imediato: utilizamos o nó mais à esquerda da subárvore direita do nó a ser removido.
- Predecessor imediato: utilizamos o nó mais à direita da subávore esquerda do nó a ser removido.
.jpg) É meus caros leitores nem no transito teremos mais privacidade, no caso a inovação da vez vem da seguradora Porto Seguro, como sua nossa aplicação ela tenta atrair os jovens e por consequência criar uma
É meus caros leitores nem no transito teremos mais privacidade, no caso a inovação da vez vem da seguradora Porto Seguro, como sua nossa aplicação ela tenta atrair os jovens e por consequência criar uma 



.jpg)
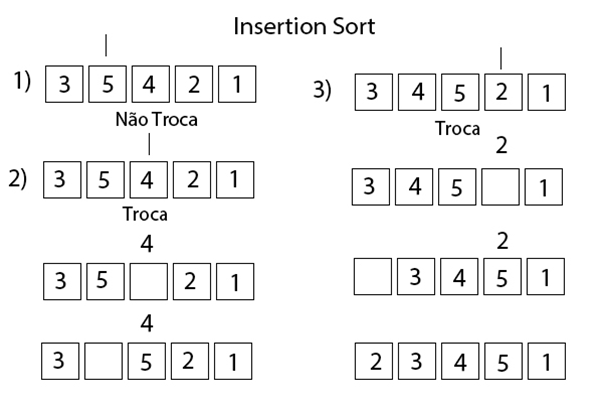






 auxiliar
auxiliar
.jpg)






.jpg)
