Com perdas e sem perdas
Esta é a forma mais conhecida de se classificar os métodos de compressão de dados. Diz-se que um método de compressão é sem perdas (em inglês, lossless) se os dados obtidos após a compressão são idênticos aos dados originais, ou os dados que se desejou comprimir. Esses métodos são úteis para dados que são obtidos diretamente por meios digitais, como textos, programas de computador, planilhas eletrônicas, etc., onde uma pequena perda de dados acarreta o não funcionamento ou torna os dados incompreensíveis. Um texto com letras trocadas, uma planilha com valores faltantes ou inexatos, ou um programa de computador com comandos inválidos são coisas que não desejamos e que podem causar transtornos. Algumas imagens e sons precisam ser reproduzidos de forma exata, como imagens e gravações para perícias, impressões digitais, etc.
Por outro lado, algumas situações permitem que perdas de dados poucos significativos ocorram. Em geral quando digitalizamos informações que normalmente existem de forma analógica, como fotografias, sons e filmes, podemos considerar algumas perdas que não seriam percebidas pelo olho ou ouvido humano. Sons de frequências muito altas ou muito baixas que os humanos não ouvem, detalhes muito sutis como a diferença de cor entre duas folhas de uma árvore, movimentos muito rápidos que não conseguimos acompanhar num filme, todos estes detalhes podem ser omitidos sem que as pessoas percebam que eles não estão lá. Nesses casos, podemos comprimir os dados simplesmente por omitir tais detalhes. Assim, os dados obtidos após a compressão não são idênticos aos originais, pois "perderam" as informações irrelevantes, e dizemos então que é um método de compressão com perdas (em inglês, lossy). Um exemplo bastante expressivo da citação acima é a imagem a seguir:

.jpg)
.jpg)











.jpg)









.jpg)
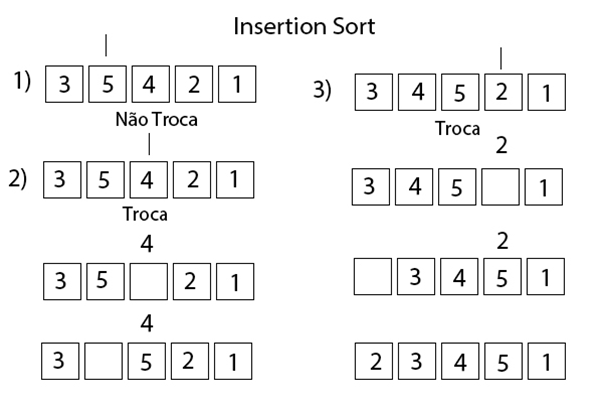






 auxiliar
auxiliar
.jpg)






.jpg)







