
Olá, nessa postagem venho falar um pouco sobre estruturas condicionais, mais especificamente a estrutura condicional "se".
Mas o que são estruturas condicionais ?
Estruturas condicionais são instruções para testar se uma condição é verdadeira ou falsa, podendo assim decidir se executa ou não um comando ou pilha de comandos.
A estrutura condicional mais básica é a estrutura "se" (no inglês, "if"), ela é encontrada em todas as linguagens (com sintaxes diferentes) e consiste em executar instruções caso uma condição se realize.
A estrutura "se" tem duas formas: simples e composta.
A forma simples apenas testa se a condição é satisfeita e executa uma ou mais instruções se a condição for verdadeira, e se for falsa a estrutura é finalizada sem executar as instruções.
Em pseudocódigo, é representado por "se" e em C é representado por "if".
A sintaxe dessa estrutura é a seguinte:
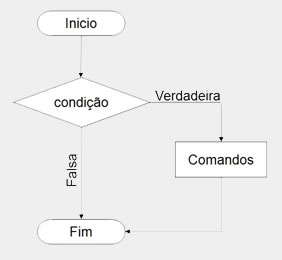
Em pseudocódigo:
se (condição) então
(lista de instruções)
fim
Em C:
if (condição) {
(lista de instruções);
}
Existe ainda a forma composta da estrutura "se", que além de testar a condição e executar as instruções no caso das condições serem verdadeiras, executa outra pilha de instruções no caso das condições serem falsas.
Em pseudocódigo é denotado por "se"..."senão", e em C: "if"..."else".
A sintaxe dessa estrutura é a seguinte:
Em pseudocódigo:
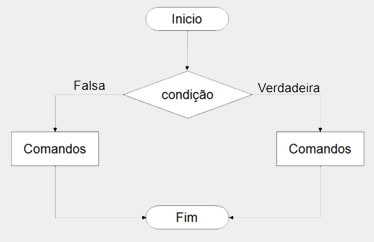
se (condição) então
(lista de instruções A)
senão
(lista de instruções B)
(lista de instruções B)
fim
Em C:
if (condição) {
(lista de instruções A);
}
else {
(lista de instruções B);
}
Se a condição for verdadeira apenas o comando A será executado, se for falsa, apenas o comando B.
As estruturas condicionais são de extrema importância na vida de um programador, pois são elas que irão decidir se serão tomadas certas ações.
Ex.: Se login e senha estiverem corretos, então é liberado o acesso, se não, é emitida uma mensagem de erro.
Espero que tenha entendido, qualquer dúvida ou sugestão deixe nos comentários.
